
{kind=link}
The Rise of the Local AI PC: From Hobbyist Tool to Everyday Powerhouse
Forget cloud subscriptions and privacy concerns. The landscape of artificial intelligence is shifting dramatically, with the ability to run powerful large language models (LLMs) directly on your PC becoming not just a possibility, but a rapidly accelerating reality. What was once a trade-off between accessibility and quality is now dissolving, thanks to newly released open-weight models like OpenAI’s gpt-oss and Alibaba’s Qwen 3. This isn’t just about tech enthusiasts; it’s a fundamental change that’s poised to democratize AI, empowering students, developers, and everyday users alike.
Unlocking AI’s Potential on Your Desktop
For years, accessing cutting-edge AI required relying on cloud-based services. While convenient, this came with limitations – data privacy concerns, subscription costs, and dependence on a stable internet connection. Now, with advancements in both model efficiency and hardware acceleration, particularly through NVIDIA RTX PCs, running LLMs locally is not only feasible but often faster. NVIDIA has been actively optimizing top LLM applications to extract maximum performance from the Tensor Cores within RTX GPUs, paving the way for a smoother, more responsive AI experience.
Getting Started is Easier Than You Think
One of the most accessible entry points is Ollama, an open-source tool that simplifies the process of downloading, running, and interacting with LLMs. Ollama’s intuitive interface allows users to drag and drop PDFs for analysis, engage in conversational chats, and even process multimodal inputs combining text and images. Recent collaborations between NVIDIA and Ollama have yielded significant performance improvements for models like OpenAI’s gpt-oss-20B and Google’s Gemma 3, alongside smarter model scheduling to optimize memory usage and multi-GPU efficiency.
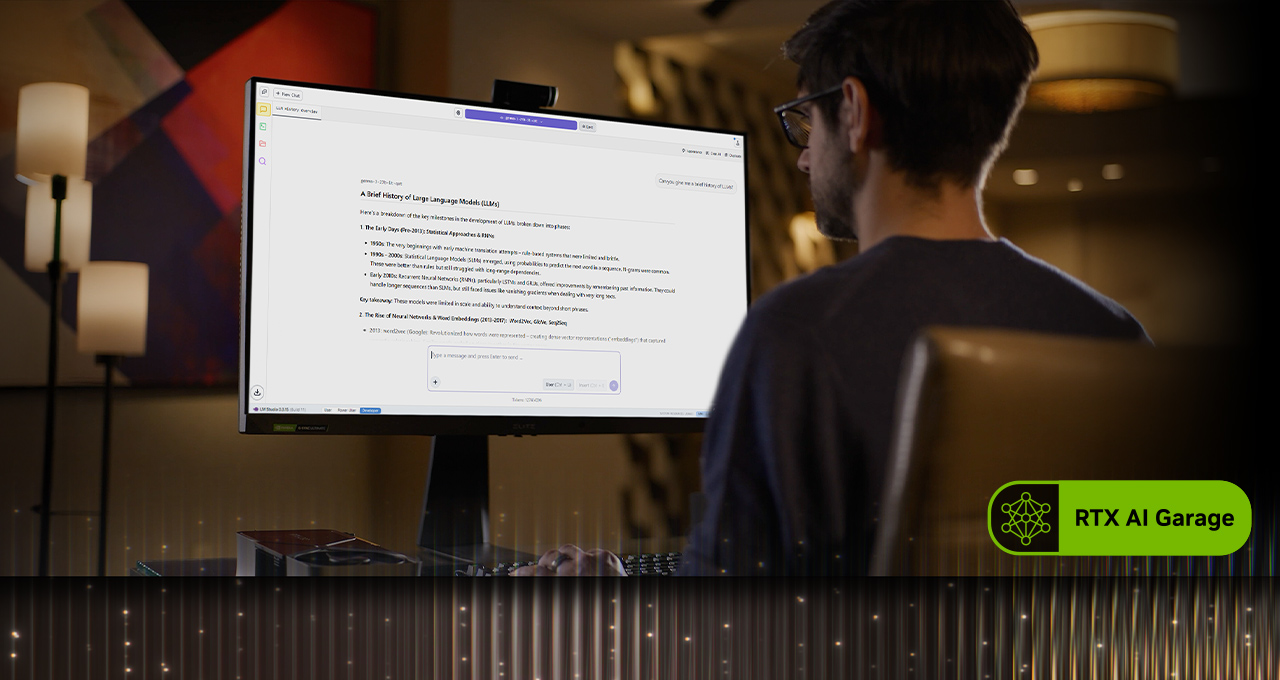
Alternatively, LM Studio, built on the popular llama.cpp framework, provides another user-friendly option. It allows users to easily load different LLMs, chat with them in real-time, and even serve them as local APIs for integration into custom projects. NVIDIA’s optimizations for llama.cpp, including support for the NVIDIA Nemotron Nano v2 9B model and the activation of Flash Attention by default (resulting in up to a 20% performance boost), further enhance the experience.
Beyond Gaming: The Expanding Applications of Local AI
The implications of readily available local LLMs extend far beyond simply chatting with an AI. The ability to process data locally, without the constraints of cloud services, unlocks new possibilities for privacy, customization, and long-term context. This is particularly impactful in education.
AI-Powered Learning: A Personalized Tutor in Your PC
Imagine a student overwhelmed with study materials – lecture slides, notes, textbooks, and past exams. Local LLMs, combined with tools like AnythingLLM, can transform this chaos into an interactive learning experience. AnythingLLM allows users to upload documents, create custom knowledge bases, and engage in conversational interfaces, effectively building a personalized AI tutor. With an RTX PC, responses are faster and more fluid. Students can:
- Generate flashcards from lecture slides with a simple prompt: “Create flashcards from the Sound chapter lecture slides. Put key terms on one side and definitions on the other.”
- Ask contextual questions based on their specific notes: “Explain conservation of momentum using my Physics 8 notes.”
- Create and grade quizzes for exam preparation: “Create a 10-question multiple choice quiz based on chapters 5-6 of my chemistry textbook and grade my answers.”
- Receive step-by-step guidance on challenging problems: “Show me how to solve problem 4 from my coding homework, step by step.”
This isn’t limited to academic pursuits. Professionals can leverage local LLMs to prepare for certifications, research complex topics, or simply streamline their workflows.
The Future is Local, Intelligent, and Personalized
The advancements don’t stop at LLMs. NVIDIA’s Project G-Assist, an experimental AI assistant, demonstrates the potential for AI to intelligently manage and optimize your PC’s performance. Recent updates allow G-Assist to control laptop settings – optimizing app profiles, managing battery life, and reducing fan noise – all through simple voice or text commands. The open-source nature of G-Assist, with its Plug-In Builder and Hub, encourages community-driven innovation and customization.
Furthermore, Microsoft’s release of Windows ML with NVIDIA TensorRT for RTX acceleration delivers up to 50% faster inference for a wide range of AI models, solidifying the RTX PC as a central hub for AI development and deployment. NVIDIA’s own Nemotron models are also fueling innovation across various industries.
The trend is clear: we’re moving towards a future where AI isn’t just accessed through the cloud, but is deeply integrated into our personal computing experiences. The combination of powerful hardware, optimized software, and increasingly accessible open-weight models is making this future a reality, and the possibilities are only beginning to be explored. What new applications will you unlock with the power of a local AI PC?