

Apple has quietly purged the 512GB Unified Memory configuration from the Mac Studio lineup. This strategic pivot suggests a shift in how Apple handles extreme LLM workloads, likely prioritizing the upcoming M5 Ultra architecture or steering enterprise AI developers toward distributed cloud compute over monolithic local workstations.
For the power user, this isn’t just a SKU change. it’s a signal. The Mac Studio was the “dark horse” of the AI revolution, providing a massive pool of Unified Memory (UMA) that allowed developers to run massive Large Language Models (LLMs) locally—tasks that usually require a cluster of NVIDIA H100s. By removing the top-tier memory ceiling, Apple is effectively redefining the boundaries of the “prosumer” workstation.
Let’s be clear: 512GB of RAM was rarely about spreadsheets or 8K video editing. It was about the KV cache and parameter scaling. When you’re running a model with hundreds of billions of parameters, your primary bottleneck isn’t raw compute—it’s VRAM. In Apple’s architecture, the GPU and CPU share the same pool of high-bandwidth memory. Removing the 512GB option creates a hard ceiling for local inference of the most massive open-weights models.
The Unified Memory Ceiling and the LLM Bottleneck
To understand why this move is jarring, you have to understand the physics of Apple’s Unified Memory Architecture. In a traditional PC, you have system RAM and GPU VRAM. Moving data between the two is a slow crawl across the PCIe bus. Apple’s SoC (System on Chip) design eliminates this trip. The GPU has direct, high-speed access to the entire memory pool.
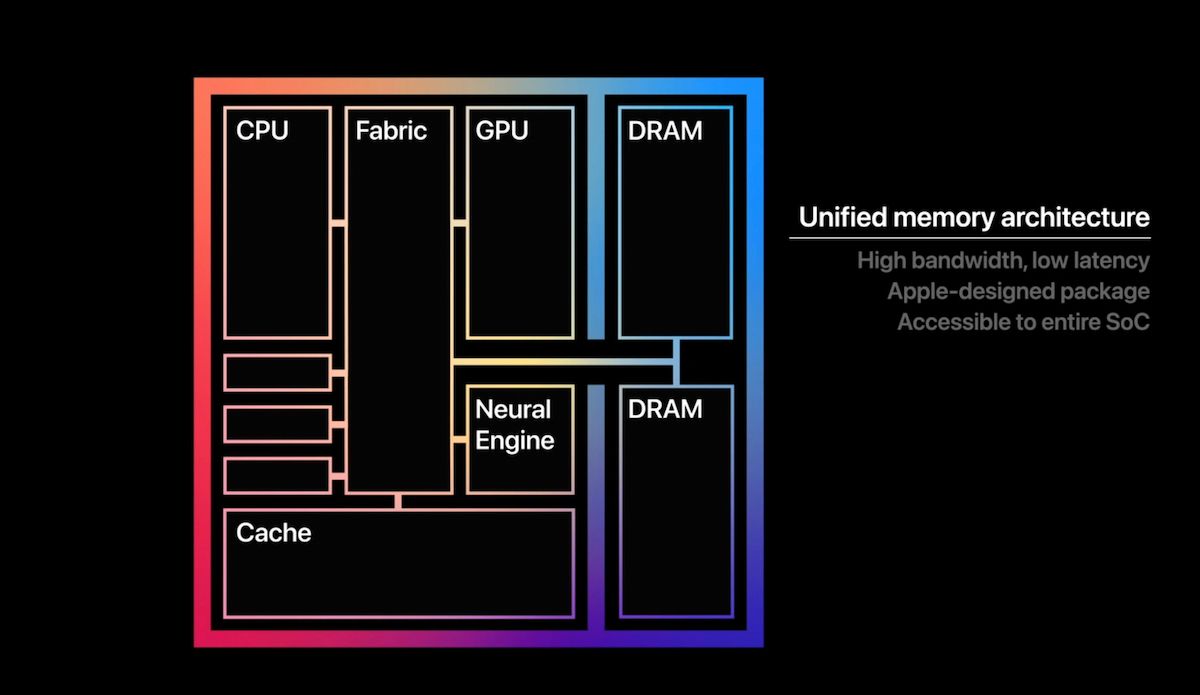
When the 512GB config existed, it allowed for the local execution of models that would otherwise require an enterprise server rack. We are talking about FP16 (half-precision) weights for models that dwarf the standard Llama-3 70B. Without that 512GB overhead, developers are forced into aggressive quantization.
Quantization is the process of reducing the precision of model weights (e.g., from 16-bit to 4-bit) to save space. While llama.cpp has made 4-bit quantization incredibly efficient, there is a tangible “perplexity hit”—a loss in the model’s nuance and reasoning capabilities. By capping the RAM, Apple is essentially telling the local AI community that “good enough” quantization is the new standard.
“The removal of the 512GB tier is a calculated move to segment the market. Apple knows that the 1% of users who actually needed half a terabyte of unified memory are no longer ‘prosumers’—they are enterprise AI labs. By capping the Studio, they push those users toward the Mac Pro or, more likely, their own cloud-based API ecosystem.” — Marcus Thorne, Lead Systems Architect at NeuralScale.
It’s a classic move in the Silicon Valley playbook: create a high ceiling to prove the tech is possible, then lower it to force a transition to a more profitable service model.
The 30-Second Verdict: Who Loses?
- ML Researchers: Those running massive MoE (Mixture of Experts) models locally now face memory overflows.
- Quantization Skeptics: Users who refuse to sacrifice precision for speed are now locked out of the Studio.
- The “Future-Proofers”: Buyers who bought 512GB for 2027’s workloads now hold a rare, high-resale asset.
Quantization vs. Capacity: The Developer’s Dilemma
If you’re a developer working in April 2026, you’re likely dealing with models that are increasingly sparse but wider. The trade-off between memory capacity and bandwidth becomes the central conflict. Even with 512GB, the memory bandwidth of the M-series chips—while impressive—still pales in comparison to the HBM3 (High Bandwidth Memory) found in dedicated AI accelerators.
People can spot the impact of this memory cap in the following capacity breakdown:
| Memory Tier | Typical Model Capability (Approx.) | Performance Impact | Primary Use Case |
|---|---|---|---|
| 192GB | Llama-3 70B (High Precision) | Optimal | Standard AI Development |
| 256GB | Llama-3 400B (Heavy Quantization) | Moderate Latency | Experimental LLM Testing |
| 512GB (Removed) | Llama-3 400B (Low Quantization) | High Throughput | Local Enterprise-Grade Inference |
By removing the 512GB tier, Apple isn’t just removing a spec; they are removing a capability. You can no longer comfortably host a high-parameter model in FP16 without hitting the swap file on your SSD, which kills performance instantly. The system begins “thrashing,” moving data between the RAM and the NVMe drive, resulting in token generation speeds that drop from “conversational” to “glacial.”
This is where the “chip wars” receive interesting. While Apple dominates the efficiency-per-watt metric, they are losing the “brute force” memory war to specialized ARM-based server chips and NVIDIA’s latest Blackwell architecture. The Mac Studio was a bridge; Apple has decided to burn that bridge to build a gated community.
The Strategic Pivot to the M5 Ultra Pipeline
Why now? The timing coincides with the whispers of the M5 Ultra’s architectural shift. Insiders suggest that the M5 series will move toward a more modular memory controller, potentially allowing for higher densities without the thermal throttling that plagued the 512GB M2/M3 Ultra configurations. High-density memory modules generate significant heat, and the Mac Studio’s thermal envelope is finite.

Apple is likely cleaning house. By removing the current top-end config, they avoid the embarrassment of shipping a “legacy” high-capacity machine right before a new architecture that handles that capacity more efficiently. It’s an inventory flush masquerading as a product refinement.
this aligns with the broader industry trend toward distributed inference. The future isn’t one giant machine; it’s a cluster of smaller, highly optimized nodes. Apple’s ecosystem is moving toward a hybrid model where the Mac Studio acts as the orchestrator, while the heavy lifting is offloaded to private cloud instances or a mesh of smaller Apple Silicon devices.
“We’ve seen this pattern before. Apple introduces a ‘hero’ spec to signal technical dominance, then streamlines the product line once the market stabilizes around a lower, more profitable average. The 512GB RAM was a flex, not a long-term product strategy.” — Sarah Jenkins, Senior Hardware Analyst.
Beyond the Mac Studio: The Cloud-Hybrid Future
The removal of the 512GB config is a nudge toward the cloud. For Apple, selling a $10,000 workstation is a one-time transaction. Selling a subscription to an AI-integrated cloud environment is a recurring revenue stream. By limiting the local hardware’s ability to run the largest models, Apple increases the gravity of its own cloud services.
This creates a precarious situation for the open-source community. The “Local AI” movement relies on the availability of consumer-grade hardware that can challenge the hegemony of closed APIs. When the hardware ceiling drops, the barrier to entry for local, private, and uncensored AI rises.
However, for the average “pro” user—the video editor, the app developer, the 3D artist—this change is invisible. They don’t need 512GB. They need 64GB or 128GB and a fast NPU. Apple is simply trimming the fat from the top of the line to make room for the next leap in SoC integration.
The Mac Studio remains a beast, but We see no longer a substitute for a server. It has returned to being a workstation. In the world of high-end computing, the “everything machine” is dead; the era of the specialized node has begun.