
{kind=link}
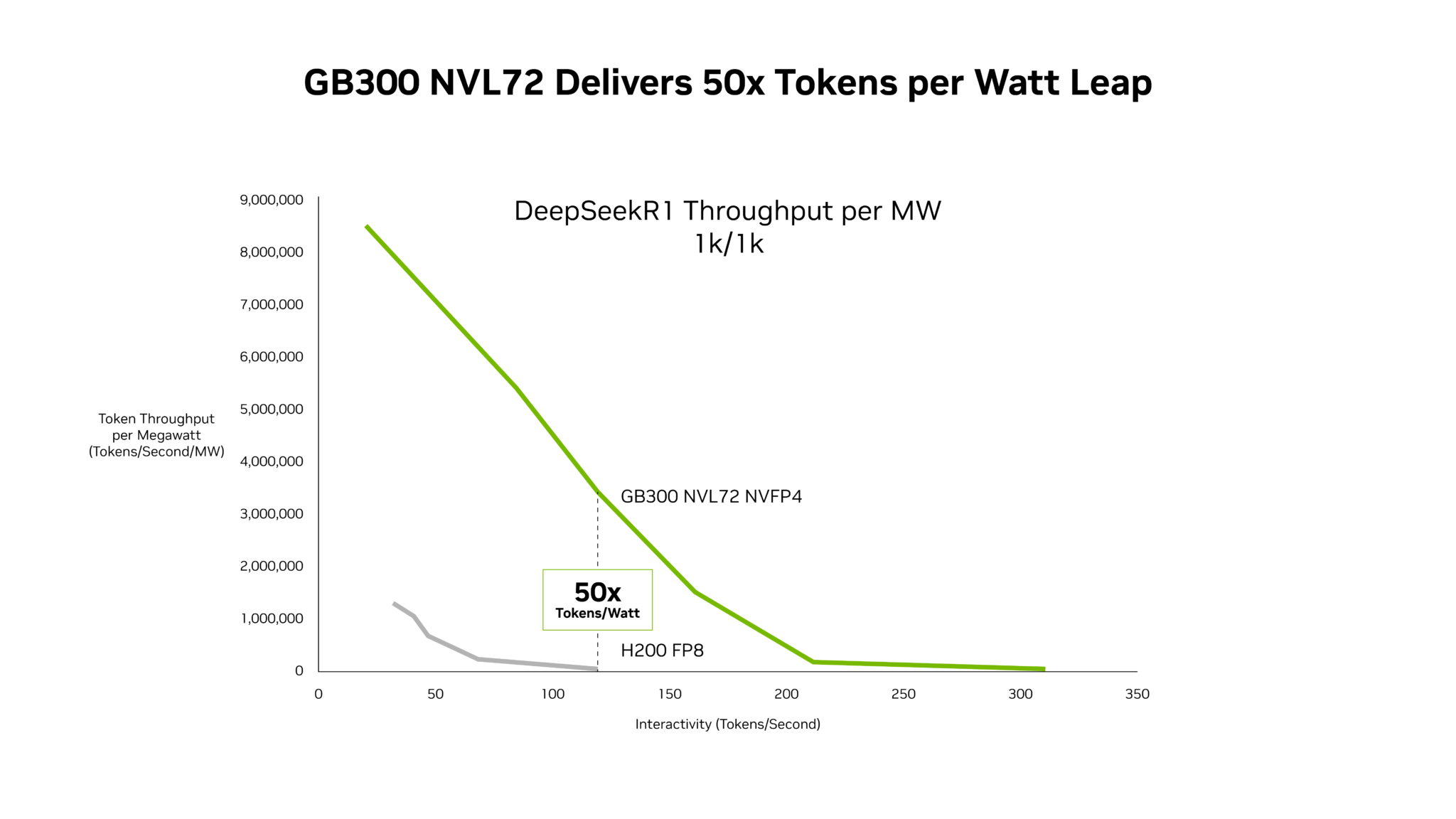
The artificial intelligence landscape is rapidly evolving, with agentic AI – AI systems capable of autonomous action – emerging as a key driver of innovation. Now, NVIDIA is unveiling significant performance gains with its Blackwell Ultra platform, promising to dramatically lower the costs and improve the efficiency of these increasingly complex AI applications. Latest data from SemiAnalysis InferenceX shows NVIDIA GB300 NVL72 systems deliver up to 50x higher throughput per megawatt and a 35x reduction in cost per token compared to the previous generation Hopper platform.
This leap in performance comes as AI agents and coding assistants are experiencing explosive growth. According to OpenRouter’s State of Inference report, software-programming-related AI queries have surged from 11% to roughly 50% in the past year. These applications demand both low latency for real-time responsiveness and the ability to process vast amounts of data – long context – when reasoning across entire codebases. The demand for efficient AI inference is becoming critical as these workloads scale.
NVIDIA’s advancements aren’t solely hardware-based. The gains are attributed to a combination of software optimizations and the next-generation Blackwell Ultra platform. This “extreme codesign” approach, encompassing chips, system architecture, and software, is accelerating performance across a range of AI workloads, from agentic coding to interactive coding assistants, whereas simultaneously driving down costs.
Significant Performance Gains with GB300 NVL72
The NVIDIA GB300 NVL72 systems are at the heart of these improvements. Analysis from Signal65 indicates that the GB200 NVL72, leveraging this codesign, delivers more than 10x more tokens per watt, resulting in one-tenth the cost per token compared to the Hopper platform. These gains are continually expanding as NVIDIA refines its software stack. Continuous optimizations to NVIDIA TensorRT-LLM, NVIDIA Dynamo, Mooncake, and SGLang are significantly boosting Blackwell NVL72 throughput for mixture-of-experts (MoE) inference.
Specifically, improvements to the NVIDIA TensorRT-LLM library have already delivered up to 5x better performance on GB200 for low-latency workloads in just the past four months. These optimizations, coupled with higher-performance GPU kernels, NVIDIA NVLink Symmetric Memory for efficient GPU-to-GPU communication, and programmatic dependent launch to minimize idle time, contribute to the overall performance boost.
Cost Reduction for Agentic Applications
The benefits of the GB300 NVL72 translate directly into economic advantages, particularly for agentic applications that require low latency. NVIDIA reports a 35x lower cost per million tokens compared to the Hopper platform. This reduction in cost is crucial for scaling real-time interactive experiences to a larger user base. For workloads involving long context – such as AI coding assistants analyzing extensive codebases with 128,000-token inputs and 8,000-token outputs – the GB300 NVL72 delivers up to 1.5x lower cost per token compared to the GB200 NVL72.
Blackwell Ultra’s enhanced capabilities, including 1.5x higher NVFP4 compute performance and 2x faster attention processing, enable agents to efficiently understand and process entire codebases. This is a critical step towards more sophisticated and capable AI assistants.
Industry Adoption and Future Developments
Major cloud providers are already integrating the new NVIDIA technology. Microsoft, CoreWeave, and Oracle Cloud Infrastructure are deploying GB300 NVL72 systems in production environments, building on earlier deployments of the GB200 NVL72. “As inference moves to the center of AI production, long-context performance and token efficiency become critical,” said Chen Goldberg, senior vice president of engineering at CoreWeave. “Grace Blackwell NVL72 addresses that challenge directly, and CoreWeave’s AI cloud… is designed to translate GB300 systems’ gains into predictable performance and cost efficiency.”
Looking ahead, NVIDIA’s Rubin platform, combining six new chips into a single AI supercomputer, promises even greater performance leaps. For MoE inference, Rubin is projected to deliver up to 10x higher throughput per megawatt compared to Blackwell, further reducing costs. The Rubin platform is too expected to significantly reduce the number of GPUs required to train large MoE models.
The advancements in NVIDIA’s Blackwell Ultra platform represent a significant step forward in making advanced AI applications more accessible and affordable. As the demand for agentic AI continues to grow, these improvements in performance and efficiency will be crucial for unlocking the full potential of this transformative technology.
What impact will these cost reductions have on the development of new AI-powered tools? Share your thoughts in the comments below.