
Mpox No Longer Global Health Emergency, But Risk Persists
Table of Contents
- 1. Mpox No Longer Global Health Emergency, But Risk Persists
- 2. declining Cases,Continued Vigilance
- 3. Understanding Mpox: A Ancient Perspective
- 4. Global Case Numbers and Geographic Distribution
- 5. The PHEIC Designation and Its Implications
- 6. Mpox Prevention and Available Treatments
- 7. Frequently Asked Questions About Mpox
- 8. What specific demographic shifts in the 2025 mpox outbreak, compared to 2022, necessitate adjustments to public health messaging?
- 9. WHO Declares Global Health Emergency Over MPOX Outbreak; Urges Immediate Action
- 10. Understanding the Current MPOX Situation
- 11. Key Symptoms and How MPOX Spreads
- 12. WHO Recommendations & Global Response
- 13. The Role of Vaccination in MPOX Prevention
- 14. Clinical Management of MPOX Cases
- 15. Addressing Misinformation and Stigma
- 16. Real-World Example: Lessons from the 2022 Outbreak
Geneva, Switzerland – The World Health Organization (WHO) has announced that the spread of Mpox, formerly known as monkeypox, no longer constitutes a global health emergency. The declaration, made in 2024, reflects a meaningful decline in cases and improved understanding of the virus, but health officials caution that the threat is not entirely extinguished.
declining Cases,Continued Vigilance
During a press conference,WHO Director-General Tedros Adhanom Ghebreyesus stated that infection numbers have been decreasing in the regions most severely impacted. He also emphasized the increased knowledge surrounding infection vectors and associated risks since the initial emergency declaration. However, Dr. Tedros stressed the importance of sustained vigilance by public health authorities worldwide. A continental health emergency remains in effect across several African nations.
Understanding Mpox: A Ancient Perspective
Mpox is not a newly emerged disease; it has been documented since the late 1950s. The illness typically presents with fever, muscular aches, and distinctive skin lesions resembling smallpox. While most infections are mild, the virus can pose a serious threat to young children and individuals with compromised immune systems. According to the European Health Authority (ECDC), the risk of infection within Europe remains low as of late July.
Recent cases reported in countries such as Germany, Great Britain, China, and Turkey have primarily been linked to travel-related exposures.
Global Case Numbers and Geographic Distribution
As of August 28,2025,the WHO has recorded 34,386 cases of Mpox and 138 deaths worldwide in 81 countries since the start of the year. A disproportionate number of cases-over 80 percent-are concentrated in the Democratic Republic of Congo, Uganda, sierra Leone, and Burundi. Public health experts acknowledge that these figures likely underestimate the true extent of the outbreak due to underreporting and limited diagnostic capabilities.
Researchers have identified different variants of the virus, including Klade IA, Klade IB, and Klade IIB, all of which are currently in circulation.
| Variant | Geographic Prevalence | Severity |
|---|---|---|
| klade IA | Central Africa | Historically higher mortality rate |
| Klade IB | West Africa | Lower mortality rate |
| Klade IIB | Global (recent outbreaks) | Variable,generally mild in vaccinated individuals |
Did You Know? The name “Mpox” was officially adopted by the WHO in November 2022 to reduce stigma and address concerns about racist and discriminatory language associated with the previous name.
The PHEIC Designation and Its Implications
The “Public Health Emergency of International Concern” (PHEIC) is the highest level of alert the WHO can issue. While it doesn’t impose direct obligations on nations, it serves as a call to action, urging governments and health organizations to prioritize response efforts and allocate resources for disease control.
pro Tip: Staying informed about local and global health advisories is crucial for proactive health management. Check the WHO and CDC websites for the latest updates.
Mpox Prevention and Available Treatments
Preventive measures against Mpox include avoiding close, personal contact with individuals exhibiting symptoms, practicing good hygiene, and safe sex practices. Vaccination is a key strategy for curbing transmission, and several vaccines have been authorized for use in various countries.
Treatment for Mpox is primarily supportive, focusing on managing symptoms and preventing secondary infections. Antiviral medications might potentially be considered in severe cases or for individuals with weakened immune systems. further research is ongoing to develop more effective therapeutics.
Frequently Asked Questions About Mpox
- What is Mpox? Mpox is a viral disease that causes fever, muscle pain, and skin lesions.
- Is mpox highly contagious? Spread typically requires prolonged, close contact with an infected individual or contaminated materials.
- Can I get vaccinated against Mpox? Yes, vaccines are available in many countries, particularly for high-risk populations.
- What should I do if I suspect I have Mpox? Contact your healthcare provider promptly for evaluation and testing.
- Is Mpox the same as smallpox? While related, Mpox is generally milder then smallpox, but can still be serious.
- What are the long-term effects of Mpox? Some individuals may experiance lingering skin changes or other complications.
- How can I protect myself from Mpox? Practice good hygiene, avoid close contact with infected individuals, and consider vaccination.
What measures do you think are most effective in preventing the spread of infectious diseases like Mpox? Share your thoughts in the comments below.
Do you feel adequately informed about mpox and the risks it poses? Let us know what additional information you’d like to see covered.
What specific demographic shifts in the 2025 mpox outbreak, compared to 2022, necessitate adjustments to public health messaging?
WHO Declares Global Health Emergency Over MPOX Outbreak; Urges Immediate Action
Understanding the Current MPOX Situation
The World Health Organization (WHO) has re-declared a global health emergency over the escalating mpox (formerly known as monkeypox) outbreak as of september 8, 2025. this decision, based on a recent surge in cases across multiple continents, underscores the urgent need for coordinated international action. The WHO’s living guideline on clinical management and infection prevention and control (IPC) for mpox https://www.who.int/publications/i/item/B09434 is being dynamically updated with new evidence, emphasizing the evolving nature of the threat.
This resurgence differs from the 2022 outbreak in several key ways, including a broader geographic spread and a shift in demographics affected. Initial outbreaks primarily impacted men who have sex with men (MSM),but current data indicates increasing transmission within and beyond these communities. This highlights the importance of inclusive public health messaging and targeted prevention strategies.
Key Symptoms and How MPOX Spreads
Recognizing the symptoms of mpox is crucial for early detection and preventing further spread. Common symptoms include:
Rash: Often resembling pimples or blisters, appearing on the face, hands, feet, mouth, or genitals.
fever: A common initial symptom.
Headache: Often accompanies the fever and rash.
Muscle aches: Can be critically important and debilitating.
Swollen lymph nodes: A characteristic feature of mpox.
Fatigue: Feeling tired and weak.
Mpox spreads through:
Direct contact: with the rash, scabs, or body fluids of an infected person.
Respiratory secretions: Through prolonged face-to-face contact.
Contaminated items: Touching items like clothing, bedding, or towels used by someone with mpox.
Animal-to-human transmission: Though less common, it can occur through bites or scratches.
Mother to fetus: During pregnancy.
WHO Recommendations & Global Response
The WHO is urging all countries to implement the following immediate actions:
- Enhanced Surveillance: Strengthen monitoring systems to rapidly identify and track new cases.This includes expanding testing capacity and improving data collection.
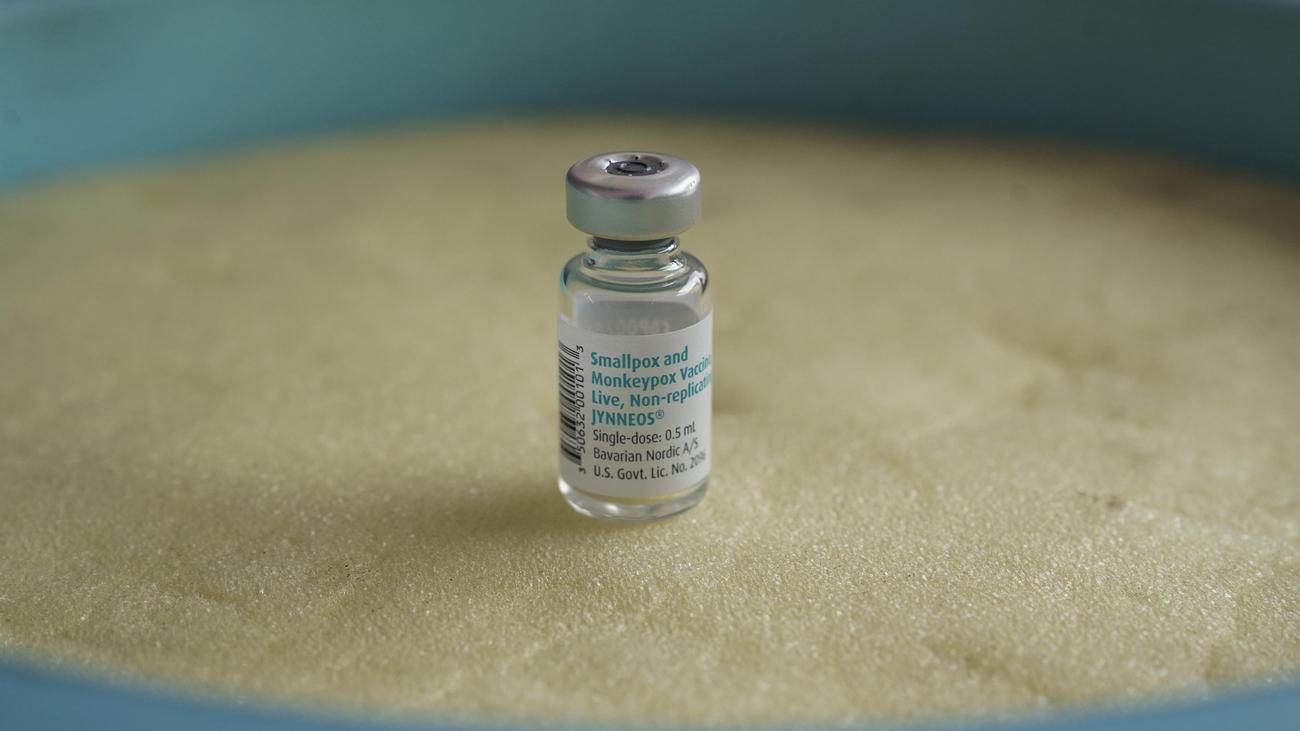
- Vaccination Programs: Prioritize vaccination for high-risk groups, including close contacts of infected individuals and healthcare workers. the JYNNEOS vaccine remains the primary preventative measure.
- Public Health Education: Launch thorough public awareness campaigns to educate the population about mpox, its symptoms, transmission routes, and prevention measures.
- Contact Tracing: Implement robust contact tracing programs to identify and monitor individuals who may have been exposed.
- Clinical Management: Ensure healthcare facilities are equipped to provide appropriate clinical care for mpox patients, following the latest WHO guidelines.
- Infection Prevention and Control (IPC): Strict IPC measures are vital in healthcare settings and communities to minimize transmission.
The Role of Vaccination in MPOX Prevention
Vaccination is a critical component of the global response to mpox. The JYNNEOS vaccine has demonstrated significant efficacy in preventing infection and reducing the severity of illness.
Two-dose regimen: The vaccine requires two doses administered 28 days apart for optimal protection.
Post-exposure prophylaxis: Vaccination is recommended for individuals who have been exposed to mpox within four days of exposure.
Pre-exposure prophylaxis: Vaccination is also recommended for high-risk individuals, even if they haven’t been exposed.
However, vaccine supply and access remain challenges in many parts of the world. Equitable distribution of vaccines is essential to protect vulnerable populations.
Clinical Management of MPOX Cases
Effective clinical management is crucial for reducing morbidity and mortality associated with mpox. Key aspects include:
Supportive care: Managing symptoms such as fever,pain,and skin lesions.
Antiviral treatment: Tecovirimat (TPOXX) is an antiviral medication approved for the treatment of mpox. Access to this treatment is being expanded globally.
Wound care: Proper wound care is essential to prevent secondary bacterial infections.
Fluid and electrolyte management: Maintaining adequate hydration is crucial, especially for patients with severe illness.
Pain management: providing appropriate pain relief to improve patient comfort.
Addressing Misinformation and Stigma
Misinformation and stigma surrounding mpox can hinder prevention efforts and discourage individuals from seeking care. It’s vital to:
Combat false narratives: Dispel myths and misconceptions about the virus and its transmission.
Promote accurate information: Share reliable information from trusted sources like the WHO and national health authorities.
Reduce stigma: Encourage empathy and understanding towards individuals affected by mpox.
* Use inclusive language: Avoid stigmatizing language and focus on facts.
Real-World Example: Lessons from the 2022 Outbreak
The 2022 mpox outbreak provided valuable lessons for the current response. Initial delays in recognizing the outbreak and implementing effective control measures contributed to its rapid spread. The current


