

Federated unlearning allows AI models to “forget” specific user data across decentralized devices without requiring full model retraining. While it satisfies GDPR’s “right to be forgotten” and enhances data privacy, it introduces critical vulnerabilities—specifically gradient leakage and model poisoning—that could potentially turn a privacy feature into a cybersecurity backdoor.
For years, the industry has treated neural network weights as a one-way street. You feed the model data, the weights shift, and that information is effectively “baked in.” But as we hit the mid-point of 2026, the regulatory pressure from the EU AI Act and similar global mandates has turned the “right to be forgotten” from a legal nuance into a technical requirement. We can’t just delete a row in a SQL database anymore; we have to excise the influence of a specific user’s data from a billion-parameter LLM distributed across ten thousand edge devices.
Enter federated unlearning (FU). It is the attempt to marry Federated Learning (FL)—where data stays on your device and only model updates are sent to the cloud—with machine unlearning. On paper, it’s a privacy dream. In practice, it’s a cryptographer’s nightmare.
The Weight of Forgetfulness: Why Neural Networks Can’t Just “Delete”
To understand why federated unlearning is so volatile, you have to understand the nature of LLM parameter scaling. When a model learns, it doesn’t store data in a folder; it distributes the “essence” of that data across millions of weights. Removing one person’s data isn’t like erasing a whiteboard; it’s like trying to remove a specific teaspoon of salt from a baked cake.
The traditional solution was “gold-standard retraining”: delete the data and train the model from scratch. But with the massive compute costs of 2026-era models, that’s economically suicidal. Instead, we use approximate unlearning. This involves calculating the “influence function” of the data to be removed and applying a reverse gradient update to “neutralize” that data’s impact on the model weights.
In a federated environment, this happens locally on the user’s NPU (Neural Processing Unit). The device calculates the necessary weight shift to “forget” the data and sends that update to the central server. It’s efficient. It’s fast. And it’s dangerously transparent.
The 30-Second Verdict: Privacy vs. Security
- The Privacy Win: Users gain actual control over their data footprint without needing to trust a central authority with their raw datasets.
- The Security Fail: The process of “unlearning” creates a mathematical trail (gradients) that can be intercepted to reverse-engineer the very data being deleted.
- The Bottom Line: Until we perfect Homomorphic Encryption for weight updates, federated unlearning is a trade-off: you trade absolute data privacy for a new surface area of cyber-attacks.
Gradient Leakage: The Backdoor in the Delete Button
Here is where the “geek-chic” optimism hits the wall of hard engineering. The very mechanism used to unlearn data—the gradient update—is a goldmine for an adversary. In a standard federated setup, we use Differential Privacy (DP) to add noise to updates, masking individual contributions. But, unlearning requires a more precise, targeted update to effectively remove specific data.
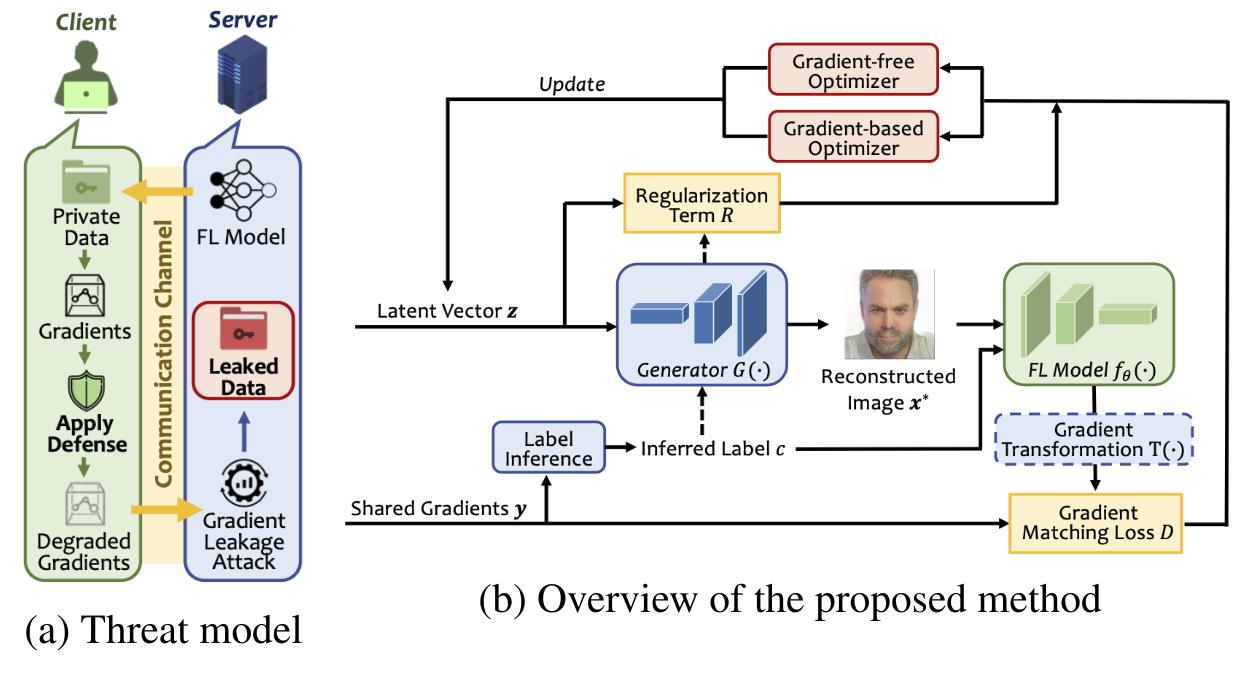
If an attacker can monitor the global model’s state before and after a federated unlearning request, they can perform a “Membership Inference Attack” (MIA). By analyzing the delta between the two versions of the model, the attacker can determine not only that a specific piece of data was present but, in some cases, reconstruct the raw input. What we have is the ultimate irony: the act of deleting your data creates a signal that confirms your data was there and reveals what it looked like.
“The paradox of machine unlearning is that to prove something has been forgotten, you must leave a trace of the forgetting process. In a decentralized network, those traces are essentially leakage vectors for any adversary capable of monitoring model versioning.”
This is not theoretical. Researchers have already demonstrated that without robust IEEE-standardized secure aggregation, these updates can be intercepted. If the unlearning process isn’t wrapped in a secure enclave (like ARM’s TrustZone or Apple’s Secure Enclave), the “forget” command is essentially a “broadcast” command to anyone listening on the wire.
The Edge Computing Paradox: NPU Power vs. Privacy Paranoia
The rollout of the latest NPU architectures in 2026 has accelerated this conflict. We now have the local compute power to run complex unlearning algorithms on-device, reducing the latency that previously made FU impractical. But this shift moves the battleground from the cloud to the edge.
When unlearning is handled by the local SoC (System on a Chip), the risk shifts toward model poisoning. A malicious actor could send a “fake” unlearning update to the central server. Instead of removing their data, they could inject a “backdoor” into the global model—a specific trigger that causes the AI to misclassify data or leak information—all under the guise of a privacy request.
| Method | Compute Cost | Privacy Level | Cybersecurity Risk | Latency |
|---|---|---|---|---|
| Full Retraining | Extreme | Absolute | Low | Days/Weeks |
| Centralized Unlearning | Medium | Low (Data must be shared) | Medium | Hours |
| Federated Unlearning | Low | High (Data stays local) | High (Gradient Leakage) | Minutes |
This creates a fragmented ecosystem. Open-source communities are pushing for transparent, verifiable unlearning protocols on GitHub, while Big Tech is leaning into closed-loop “Private Cloud Compute” environments. The latter attempts to solve the leakage problem by ensuring the unlearning happens in a hardware-attested environment where even the cloud provider can’t see the gradients.
Navigating the Regulatory Minefield of the EU AI Act
As we see in this week’s beta releases of several major enterprise AI frameworks, the focus is shifting toward “Verifiable Unlearning.” The goal is to provide a cryptographic proof that data has been removed without revealing the data itself. This likely involves Zero-Knowledge Proofs (ZKPs), where the device proves the weight update was performed correctly without exposing the gradient vector.
But ZKPs are computationally expensive. Even with 2026’s NPU gains, the overhead can be significant, leading to a “privacy tax” on performance. Developers are now forced to choose between three suboptimal paths: sluggish and secure, fast and leaky, or compliant and expensive.
For the enterprise, the risk is no longer just a fine from a regulator; it’s a systemic vulnerability. If a competitor can trigger mass unlearning requests and use the resulting model shifts to map out a company’s proprietary training set, the intellectual property loss would be catastrophic. We are moving from an era of “data theft” to an era of “model interrogation.”
The path forward requires a fundamental rethink of how we store “knowledge” in AI. Until we move away from monolithic weight matrices toward more modular, sparse architectures—where data is stored in discrete, addressable “neurons”—federated unlearning will remain a precarious balancing act. For now, the “delete” button in AI is less of a shredder and more of a signal flare.