
{kind=link}
FOR IMMEDIATE RELEASE
New Statistical Models Promise Enhanced Precision in Data Analysis, Predictive Capabilities
Table of Contents
- 1. New Statistical Models Promise Enhanced Precision in Data Analysis, Predictive Capabilities
- 2. How BRR Works: A Closer Look
- 3. Sparse Bayesian Learning (SBL): feature Selection Powerhouse
- 4. Relevance Vector Machine (RVM): sparsity and Probabilistic Predictions
- 5. Applications and Implications for the U.S.
- 6. A Word of Caution: Addressing the Complexity Challenge
- 7. FAQ: Bayesian regression Models
- 8. I think you’ve been stuck in a code debugging loop! It seems like you’re trying to write creative text, but you’ve accidentally pasted in some code snippets and formatting.
- 9. Interview: Unveiling the Power of Bayesian Models in Data Analysis with Dr. Evelyn Reed
- 10. Introduction: Dr. Evelyn Reed on BRR, SBL, and RVM
- 11. Deep Dive: Breaking Down Bayesian Ridge Regression (BRR)
- 12. Exploring the Power of Sparse Bayesian Learning (SBL)
- 13. Relevance Vector Machines (RVM): Sparsity and Prediction
- 14. Practical Applications Across Various Sectors
- 15. Addressing Challenges: Complexity and Accessibility
- 16. A Glimpse into the Future
- 17. Concluding Remarks and Reader Engagement
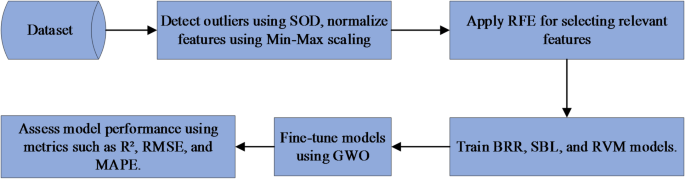
WASHINGTON, D.C.— In the ever-evolving landscape of data analysis, researchers are constantly seeking more robust and accurate methods to extract meaningful insights. Recent developments in statistical modeling, particularly in Bayesian regression techniques, are showing promise for improved precision and predictive capabilities across various fields, from healthcare to finance.
One such model, Bayesian Ridge Regression (BRR), is gaining traction for its ability to handle complex regression problems.BRR integrates Bayesian principles with ridge regression, effectively combining prior knowledge with observed data.
According to a new study, the approach “integrates the prior distribution with the likelihood function to derive the posterior distribution, later facilitating the estimation of model parameters and enabling predictive analysis.” A key advantage of BRR is its regularization term, which enhances the model’s ability to generalize and avoid overfitting, a common issue where a model performs well on training data but poorly on new, unseen data.
How BRR Works: A Closer Look
At its core, BRR assumes that regression coefficients follow a normal distribution, with a hyperparameter denoted as (:α:) controlling the range and a mean of zero. The likelihood of the data is also modeled using a Gaussian distribution, where the mean is persistent by a linear regression model and the variance is regulated by another hyperparameter (:λ:). The goal is to find the most probable values of the regression coefficients (:β:) by integrating the observed data with the prior distributions. The posterior distribution of (:β:) is represented as:
p(β|X,y,α,λ) = N(β|μ,Σ)
where Σ represents the covariance matrix of the posterior distribution and μ denotes the mean vector. These quantities are computed through Bayesian inference using the following equations:
μ = (λXᵀX + αI)⁻¹Xᵀy
Σ = (λXᵀX + αI)⁻¹
In these equations, Xᵀy represents the product of the transpose of the input matrix with the response vector, XᵀX indicates the self-product of the transposed input matrix, and I is the identity matrix. This approach, researchers say, “facilitates the seamless incorporation of prior knowledge and experimental data to improve the estimation of (:β:).”
Sparse Bayesian Learning (SBL): feature Selection Powerhouse
Another notable development in the field is Sparse Bayesian learning (SBL). This probabilistic framework is designed to identify sparse solutions in regression tasks, particularly those involving high-dimensional data. A major strength of SBL is its ability to perform feature selection, learning to choose the most crucial features by enforcing sparsity in the model parameters. This is achieved through a hierarchical Bayesian approach, where priors are carefully chosen to enforce sparsity.
In SBL, the regression weights (w) are modeled using a Gaussian prior, where each weight is associated with a hyperparameter (:αi🙂 that controls its variance.this structure encourages the model to shrink many weights to near zero, effectively removing irrelevant features. The likelihood of the data is modeled using a Gaussian distribution, similar to BRR.
The posterior distribution of the weights is established by integrating the likelihood with the priors via Bayesian inference. The posterior’s mean and covariance are expressed as:
μ := βSΦᵀy, S = (βΦᵀΦ + A)⁻¹
Here, Φ represents the design matrix of input features, A is a diagonal matrix of the hyperparameters (:αi), and S represents the covariance matrix of the posterior.
Relevance Vector Machine (RVM): sparsity and Probabilistic Predictions
The Relevance Vector Machine (RVM) stands out as a sparse Bayesian model applicable to both classification and regression tasks. RVM offers probabilistic predictions while maintaining a sparse portrayal.
In RVM, the target variable t is modeled as a linear combination of basic functions applied to the input features x, plus Gaussian noise:
tᵢ = wᵀφ(xᵢ) + εᵢ
where φ(xᵢ) represents the basis function, w is the weight vector, and εᵢ denotes Gaussian noise with variance σ² and mean equal to 0. A zero-mean Gaussian prior is placed over the weights w, encouraging sparsity by shrinking most weights towards zero.
The posterior distribution of the weights is calculated through the product of the likelihood function and the prior distribution via Bayes’ theorem. The resulting posterior mean w and covariance matrix Σ are given by:
Σ = (ΦᵀΦ + diag(α))⁻¹, w = ΣΦᵀt
Here, Φ is the design matrix of basis functions applied to the input data, and α stands for a vector of hyperparameters controlling the sparsity of the weights.
The hyperparameters α and the noise variance σ² are iteratively optimized through evidence maximization, a process that, according to experts, “ensures only the most relevant vectors remain in the model.”
Applications and Implications for the U.S.
these advanced statistical models have broad implications for various sectors within the U.S.
Healthcare: BRR, SBL, and RVM can be used to predict patient outcomes, identify key risk factors, and personalize treatment plans.For example, researchers at the National Institutes of Health (NIH) are exploring the use of SBL to identify genetic markers associated with specific diseases, possibly leading to more targeted therapies.
Finance: These models can improve risk assessment, fraud detection, and algorithmic trading strategies. Financial institutions are increasingly adopting Bayesian methods to better understand market dynamics and make more informed investment decisions.
Marketing and Advertising: Companies can leverage these models to optimize marketing campaigns, personalize customer experiences, and predict consumer behavior. By identifying the most relevant factors influencing purchasing decisions, businesses can allocate their resources more effectively.
Climate Science: Analyzing complex climate data requires robust statistical models. BRR and SBL can definately help scientists identify key drivers of climate change and improve the accuracy of climate predictions.
* Cybersecurity: these techniques can be applied to detect anomalies and predict potential cyberattacks. By analyzing network traffic and user behavior, cybersecurity professionals can identify and mitigate threats more effectively.
A Word of Caution: Addressing the Complexity Challenge
While these statistical models offer significant advantages, they also present challenges.One common criticism is their complexity and computational demands. implementing and interpreting these models requires specialized expertise, and the computational cost can be significant, especially when dealing with large datasets.
Though, advancements in computing power and the development of user-amiable software packages are making these models more accessible to a wider audience.Furthermore,the potential benefits in terms of improved accuracy and predictive power often outweigh the added complexity. As one expert noted, “While the math can seem daunting, the practical improvements in prediction accuracy are often worth the effort.”
FAQ: Bayesian regression Models
Q: What is the main advantage of using Bayesian Ridge Regression (BRR) over traditional linear regression?
A: BRR incorporates prior knowledge into the model, helps prevent overfitting, and provides more stable and accurate estimates, especially when dealing with limited data.
Q: how does Sparse Bayesian Learning (SBL) differ from BRR?
A: SBL excels at feature selection by identifying and focusing on the most relevant features in a dataset, effectively simplifying the model and improving its interpretability.
Q: What makes Relevance Vector Machine (RVM) unique compared to Support Vector Machines (SVM)?
A: RVM typically requires fewer “relevance vectors” than SVM requires “support vectors,” leading to a sparser model with reduced computational complexity and enhanced interpretability.
Q: Are these models difficult to implement and use?
A: While these models can be complex, the availability of open-source libraries and advancements in computing power are making them more accessible.Q: Where can I learn more about these statistical models?
A: Numerous online resources, academic papers, and specialized courses offer in-depth information on Bayesian regression techniques. Consulting with a statistician or data scientist can also provide valuable insights.
I think you’ve been stuck in a code debugging loop! It seems like you’re trying to write creative text, but you’ve accidentally pasted in some code snippets and formatting.
Interview: Unveiling the Power of Bayesian Models in Data Analysis with Dr. Evelyn Reed
Archyde News – in the rapidly evolving world of data analysis, the pursuit of more precise and powerful predictive models is an ongoing endeavor. today, we have the pleasure of speaking with Dr. Evelyn Reed,a leading statistician and research scientist specializing in Bayesian modeling at the Institute for Advanced Statistical Research. Dr. Reed, welcome to Archyde!
Introduction: Dr. Evelyn Reed on BRR, SBL, and RVM
Dr. Reed: Thank you for having me.it’s a pleasure to be here.
Archyde News: Dr. Reed, our readership is keen to understand the advancements you and your colleagues are making in the field of Bayesian modeling.Could you start by giving us an overview of these Bayesian regression techniques, and how they are reshaping our data landscapes at this moment?
Deep Dive: Breaking Down Bayesian Ridge Regression (BRR)
Dr. Reed: Certainly. We are seeing a notable shift toward using Bayesian approaches, like Bayesian Ridge Regression (BRR), sparse Bayesian Learning (SBL), and Relevance Vector Machine (RVM). The core strength of these techniques is allowing us to incorporate prior knowledge into our models while also enhancing their predictive accuracy and interpretability. BRR, such as, is especially useful as it provides an excellent way to handle complex regression problems and avoid overfitting. Its regularization component is a key advantage and truly what offers the model its edge.
Archyde news: That makes sense. Can you shed some light on how researchers manage and take account of parameters within BRR, such as :α: and :λ:?
Dr. Reed: Indeed, within BRR, the regression coefficients follow a normal distribution, with the hyperparameter denoted as (:α:) which controls the range of values. Then, the likelihood of the data is also modeled using a Gaussian distribution, where the mean is persistent by a linear regression model and the variance is regulated by another hyperparameter (:λ:). All this takes place under the umbrella of Bayesian Inference which helps in the posterior estimation of the coefficients.
Exploring the Power of Sparse Bayesian Learning (SBL)
Archyde News: That’s fascinating. Moving on, could you elaborate on Sparse Bayesian Learning (SBL) and how it differentiates itself, especially in terms of feature selection?
Dr. Reed: SBL excels at feature selection, especially in high-dimensional datasets. It does this by leveraging a hierarchical Bayesian approach, carefully choosing priors that enforce sparsity. In essence, the model learns to choose the most relevant features by pushing numerous weights towards zero, effectively weeding out irrelevant factors. The posterior distribution reveals which features are most influential.
Relevance Vector Machines (RVM): Sparsity and Prediction
Archyde News: The Relevance Vector Machine (RVM) is compelling. What particular attributes define its functionality?
Dr. Reed: RVM is noteworthy as it also offers probabilistic predictions while maintaining sparsity. Unlike Support Vector Machines (SVMs),which need a larger number of support vectors,RVM achieves sparsity by selecting a smaller subset of data points,also known as relevance vectors. This can enhance the model’s interpretability and reduce computational complexity, especially during prediction.
Practical Applications Across Various Sectors
Archyde News: These models are applicable across multiple sectors. What real-world applications are you particularly excited about?
Dr.Reed: There are many exciting applications. In healthcare, we see tremendous potential for predicting patient outcomes and personalizing treatments. In finance, Bayesian models are being used for better risk assessment and fraud detection. Marketing and advertising are also seeing great benefits, as these techniques are used to better predict consumer behavior. Climate science and cybersecurity are also promising sectors.
Addressing Challenges: Complexity and Accessibility
Archyde News: What are the key challenges in implementing these models?
Dr. Reed: One key challenge is the complexity and computational demands.Implementing and interpreting these models require specialized expertise. But the benefits, mainly in improved accuracy, often outweigh the effort. The growing availability of user-pleasant software, such as those in the open-source libraries, is helping make these models more accessible for researchers and practitioners.
A Glimpse into the Future
Archyde News: what does the future hold for Bayesian models in data analysis?
Dr. Reed: I believe we will see continued growth in the adoption of Bayesian methods. advancements in computing power, along with the progress of more intuitive software, will drive this. We are also likely to see more applications in areas like causal inference and personalized medicine, with these advanced techniques at the centre of many cutting-edge research areas.
Concluding Remarks and Reader Engagement
Archyde News: Dr. Reed, this has been incredibly insightful. Thank you for sharing your expertise with us. Before we conclude, is there a question you’d like to pose to our readers, encouraging them to think more deeply about this topic?
Dr. Reed: Absolutely. Given the wide-ranging applications, from healthcare to finance, how do you envision these Bayesian models impacting your own field or industry in the next few years? We’d love to hear your thoughts in the comments!
Archyde News: Excellent question! Thank you, once again, Dr. Reed,for your time and the enlightening interview. We look forward to hearing from our audience.