
{kind=link}
“`html
Google DeepMind Unveils ‘ATLAS’ – new Scaling laws for Multilingual AI Models
Table of Contents
- 1. Google DeepMind Unveils ‘ATLAS’ – new Scaling laws for Multilingual AI Models
- 2. The Challenge of Multilingual AI
- 3. Cross-Lingual Transfer: A Key Finding
- 4. Quantifying the ‘Curse of Multilinguality’
- 5. Pre-Training vs. Fine-Tuning: A Computational Trade-off
- 6. Implications for Future AI Development
- 7. what is ATLAS in the context of multilingual language models?
- 8. ATLAS: A New Scaling Law for Multilingual language Models
- 9. Understanding Traditional Scaling Laws
- 10. Introducing ATLAS: A Refined Approach
- 11. How ATLAS Differs from Previous Models
- 12. Practical Implications for Developers
- 13. Real-World Applications & Case studies
- 14. Benefits of Adopting ATLAS Principles
Mountain View, California – January 29, 2026 – Google DeepMind has announced a breakthrough in the development of multilingual Artificial Intelligence, introducing a new set of scaling laws dubbed “ATLAS.” This research formalizes the complex interplay between model size, the volume of training data, and the diverse mix of languages as the number of supported languages expands. The findings, stemming from 774 controlled experiments involving models from 10 million to 8 billion parameters, cover over 400 languages and assess performance across 48 specific languages.
The Challenge of Multilingual AI
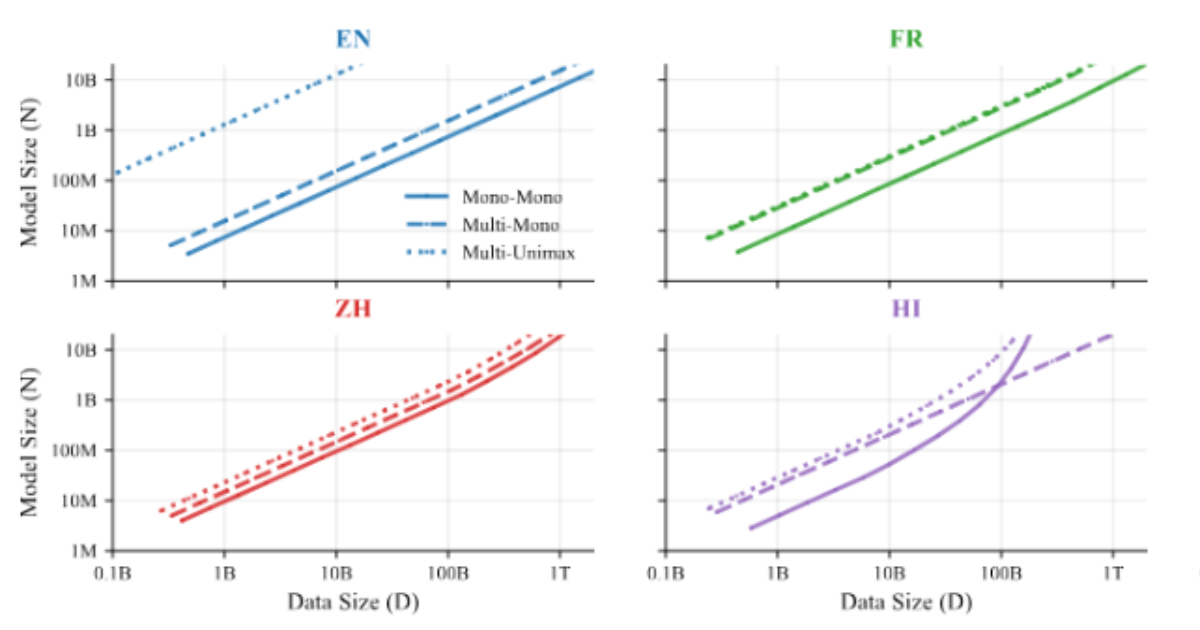
Traditionally, scaling laws in the field of language models have primarily focused on English or single-language contexts. These existing models have limited applicability when applied to systems designed to process multiple languages simultaneously. The ATLAS framework addresses this gap by specifically modeling cross-lingual transfer—how knowledge gained from one language benefits another—and the inherent trade-offs in efficiency when training multilingual systems. This new approach moves beyond the assumption that adding each language has a uniform impact on overall performance.
Cross-Lingual Transfer: A Key Finding
At the heart of the ATLAS research lies a “cross-lingual transfer matrix” designed to quantify the influence of training on one language on the performance of others. The analysis reveals a strong correlation between positive transfer and linguistic similarities, such as shared writing systems and language families. For instance, Scandinavian languages demonstrate mutual benefits during training.Similarly, Malay and Indonesian exhibit a high degree of transfer. English, french, and Spanish consistently prove valuable source languages, likely attributable to the sheer volume and diversity of available data, although these transfer effects are not always symmetrical.
Quantifying the ‘Curse of Multilinguality’
The study identifies what researchers term the “curse of multilinguality”—the tendency for per-language performance to decrease as the number of supported languages increases within a fixed-capacity model. According to the ATLAS findings, doubling the number of languages requires a roughly 1.18-fold increase in model size and a 1.66-fold increase in total training data to maintain equivalent performance levels. Though, positive cross-lingual transfer partially mitigates this issue by offsetting the reduction in data allocated to each individual language.
Pre-Training vs. Fine-Tuning: A Computational Trade-off
Researchers also investigated the optimal approach for developing multilingual models: pre-training from scratch versus fine-tuning an existing multilingual checkpoint. The results indicate that fine-tuning is more computationally efficient when working with smaller datasets.Though, pre-training becomes more advantageous as training data and computational resources increase. For 2 billion-parameter models, the shift in favor of pre-training typically occurs between 144 billion and 283 billion tokens, offering a practical guideline for developers based on available resources.
Implications for Future AI Development
The release of ATLAS has sparked debate about the future of model architecture. Some experts are questioning whether massive, all-encompassing models are the most efficient path forward.Online discussions, such as one on X (formerly Twitter), suggest exploring specialized or modular designs. One user posited, “rather than an enormous model trained on redundant data from every language, how large would a purely translation model need to be, and how much smaller would it make the base model?” While ATLAS doesn’t directly address this question, the framework provides a solid quantitative
what is ATLAS in the context of multilingual language models?
ATLAS: A New Scaling Law for Multilingual language Models
The landscape of Natural Language Processing (NLP) is constantly evolving, and recent advancements in scaling laws are pushing the boundaries of what’s possible with multilingual language models. Enter ATLAS, a novel approach that redefines how we understand and predict the performance of these models as they grow in size and complexity. This article dives deep into the core principles of ATLAS, its implications for developers and researchers, and how it compares to existing scaling laws.
Understanding Traditional Scaling Laws
Before we explore ATLAS, it’s crucial to understand the foundation it builds upon. Traditional scaling laws, like those initially observed with GPT-3, generally follow a power-law relationship. This means that performance (measured by metrics like perplexity or accuracy) improves predictably as you increase:
* Model Size (Parameters): The number of trainable parameters within the model.
* dataset Size (Tokens): The amount of text data used for training.
* Compute: The total computational resources used during training.
These laws allowed researchers to estimate the performance gains achievable by simply increasing these factors. However, they often fell short when applied to multilingual models, exhibiting inconsistencies and requiring larger datasets for comparable results. This is where ATLAS steps in.
Introducing ATLAS: A Refined Approach
ATLAS (Adaptive Training and Learning for Scalable Multilingual Systems) proposes a more nuanced understanding of scaling behavior in multilingual contexts. It identifies that the relationship between model size, data, and performance isn’t uniform across all languages. Instead, it’s adaptive, meaning it changes based on the linguistic characteristics of the language being modeled.
key findings of the ATLAS research include:
- Language-Specific Scaling: Languages with richer morphology (like Turkish or Finnish) or more complex syntax often require considerably more data to achieve the same level of performance as languages like English.ATLAS accounts for this by incorporating a “linguistic complexity factor” into its scaling predictions.
- Transfer Learning Efficiency: ATLAS demonstrates that pre-training on a diverse multilingual corpus and then fine-tuning on a specific language yields better results than training a monolingual model from scratch,even with comparable data sizes.This highlights the power of cross-lingual transfer learning.
- Data Quality Matters More: While quantity is crucial, ATLAS emphasizes the critical role of data quality. Clean, well-curated datasets, even if smaller, can outperform larger, noisy datasets, notably for low-resource languages.
How ATLAS Differs from Previous Models
Existing scaling laws often treat all languages as equal, leading to inaccurate predictions for multilingual models. Here’s a direct comparison:
| Feature | Traditional Scaling Laws | ATLAS |
|---|---|---|
| Language Consideration | Assumes uniform scaling across languages | Accounts for linguistic complexity |
| Data Requirements | Predicts based on overall dataset size | Predicts based on language-specific data needs |
| Transfer Learning | Less emphasis on cross-lingual transfer | Highlights the benefits of pre-training and fine-tuning |
| Data Quality | Focuses primarily on quantity | Prioritizes both quantity and quality |
Practical Implications for Developers
ATLAS isn’t just a theoretical advancement; it has tangible implications for developers building and deploying multilingual language models:
* Resource Allocation: When training a multilingual model, allocate more computational resources and data to languages with higher linguistic complexity.
* data Curation: Invest in high-quality data curation, especially for low-resource languages. This includes cleaning, filtering, and potentially augmenting existing datasets.
* Transfer Learning Strategies: Leverage pre-trained multilingual models as a starting point for your projects. Fine-tuning on language-specific data will likely yield better results than training from scratch.
* Model Evaluation: evaluate model performance on a diverse set of languages,not just high-resource ones like english. Use language-specific metrics to get a more accurate assessment.
Real-World Applications & Case studies
Several organizations are already leveraging the principles of ATLAS to improve their multilingual NLP applications. Such as:
* Meta’s NLLB (No Language Left Behind) project: This initiative, aiming to build high-quality machine translation models for over 200 languages, heavily incorporates transfer learning and data augmentation techniques aligned with ATLAS principles. Early results show meaningful improvements in translation quality for low-resource languages.
* Google Translate: Google continues to refine its translation models using insights from scaling laws, including those related to data quality and language-specific needs. Improvements in handling morphologically rich languages are a direct result of this research.
* Academic Research: Universities worldwide are using ATLAS to guide the growth of new multilingual models for tasks like sentiment analysis, text summarization, and question answering.
Benefits of Adopting ATLAS Principles
Implementing ATLAS-informed strategies offers several key benefits:
* Improved Performance: Achieve higher accuracy and fluency