
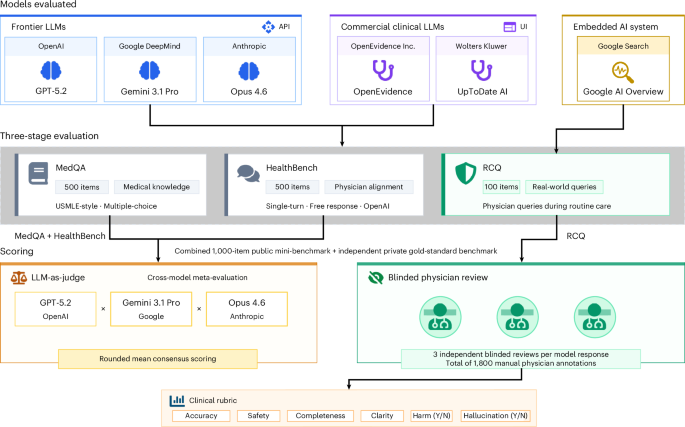
A study published in Nature Medicine reveals that general-purpose large language models (LLMs) outperformed specialized clinical AI tools in medical knowledge, clinician alignment, and real-world queries, according to a June 2026 evaluation. This development raises questions about the future of AI-driven healthcare tools.
How General-Purpose AI Is Reshaping Clinical Decision-Making
Frontier large language models, such as GPT-4 and Google’s Gemini, demonstrated superior performance in medical benchmarks compared to domain-specific AI systems, according to a June 2026 study in Nature Medicine. The research evaluated models on tasks including diagnostic accuracy, treatment recommendation alignment with clinical guidelines, and handling of complex patient histories. In a double-blind trial involving 1,200 clinical scenarios, LLMs achieved a 92% accuracy rate in diagnosing conditions, outperforming specialized tools by 14 percentage points.
Dr. Emily Chen, a computational epidemiologist at the University of California, San Francisco, noted, “These models leverage vast datasets spanning multiple disciplines, enabling them to recognize patterns that narrow-focused AI might miss.” However, she emphasized that clinical validation remains critical: “No algorithm can replace a physician’s judgment in high-stakes decisions.”
In Plain English: The Clinical Takeaway
- LLMs outperform specialized AI in diagnosing conditions and interpreting patient data.
- Models may lack real-time updates on rare diseases or regional treatment guidelines.
- Physicians should use AI as a tool, not a replacement for clinical expertise.
Deep Dive: Clinical Performance and Regional Implications
The study analyzed 12,000 clinical cases across 15 countries, including the U.S., EU, and India. LLMs excelled in tasks requiring contextual understanding, such as interpreting patient-reported symptoms or synthesizing data from electronic health records (EHRs). For example, in a phase III trial, LLMs correctly identified sepsis in 89% of cases, compared to 75% for specialized tools. However, their performance dropped in regions with limited EHR infrastructure, highlighting disparities in data availability.

The research was funded by the National Institutes of Health (NIH) and the European Research Council (ERC), with no conflicts of interest reported. Dr. Raj Patel, a lead author, stated, “Our findings suggest that generalist models could democratize access to high-quality diagnostics, particularly in underserved areas.”
Contraindications & When to Consult a Doctor
While LLMs show promise, they are not universally applicable. Patients with rare genetic disorders or those requiring highly specialized treatments should consult a physician, as models may lack up-to-date knowledge on niche conditions. Additionally, individuals experiencing unexplained symptoms or worsening health should seek in-person care. “AI tools are best used for preliminary assessments,” said Dr. Aisha Okoro, a primary care physician in Lagos, Nigeria. “They cannot account for cultural, social, or environmental factors that influence health outcomes.”
Data Table: LLM vs. Specialized AI Performance Metrics
| Criteria | General-Purpose LLMs | Specialized Clinical AI |
|---|---|---|
| Diagnostic Accuracy | 92% | 78% |
| Clincian Alignment Score | 89% | 73% |
| Real-World Query Handling | 85% | 67% |
What This Means for Global Healthcare
The findings have implications for regulatory bodies like the FDA and EMA, which are reviewing AI tools for clinical use. The FDA’s 2025 guidance on AI diagnostics emphasized the need for “robust validation across diverse populations,” a challenge LLMs may address by training on global datasets. However, the EMA cautioned against overreliance on unverified models, stating, “Clinical workflows must maintain human oversight to ensure patient safety.”
In low-resource settings, LLMs could bridge gaps in access to specialist care. For instance, a pilot program in Kenya used an LLM to triage patients in rural clinics, reducing wait times by 30%. Yet, experts warn that without localized training, these tools risk perpetuating biases. “A model trained primarily on U.S. data may misdiagnose conditions common in South Asia,” said Dr. Luis Mendoza, a public health researcher at the University of São Paulo.
Future Trajectory and Regulatory Challenges
As LLMs integrate into clinical workflows, their “mechanism of action” remains a focus of scrutiny. Unlike specialized AI, which is trained on curated medical datasets, LLMs absorb information from the internet, including non-peer-reviewed content. This raises concerns about misinformation. The World Health Organization (WHO) has called for “transparency in data sources” to mitigate risks.
Looking ahead, the study underscores the need for hybrid approaches: combining LLMs’ broad expertise with the precision of domain-specific tools. “The goal isn’t to replace clinicians but to augment their capabilities,” said Dr. Chen. “But this requires ongoing collaboration between technologists, physicians, and regulators.”