
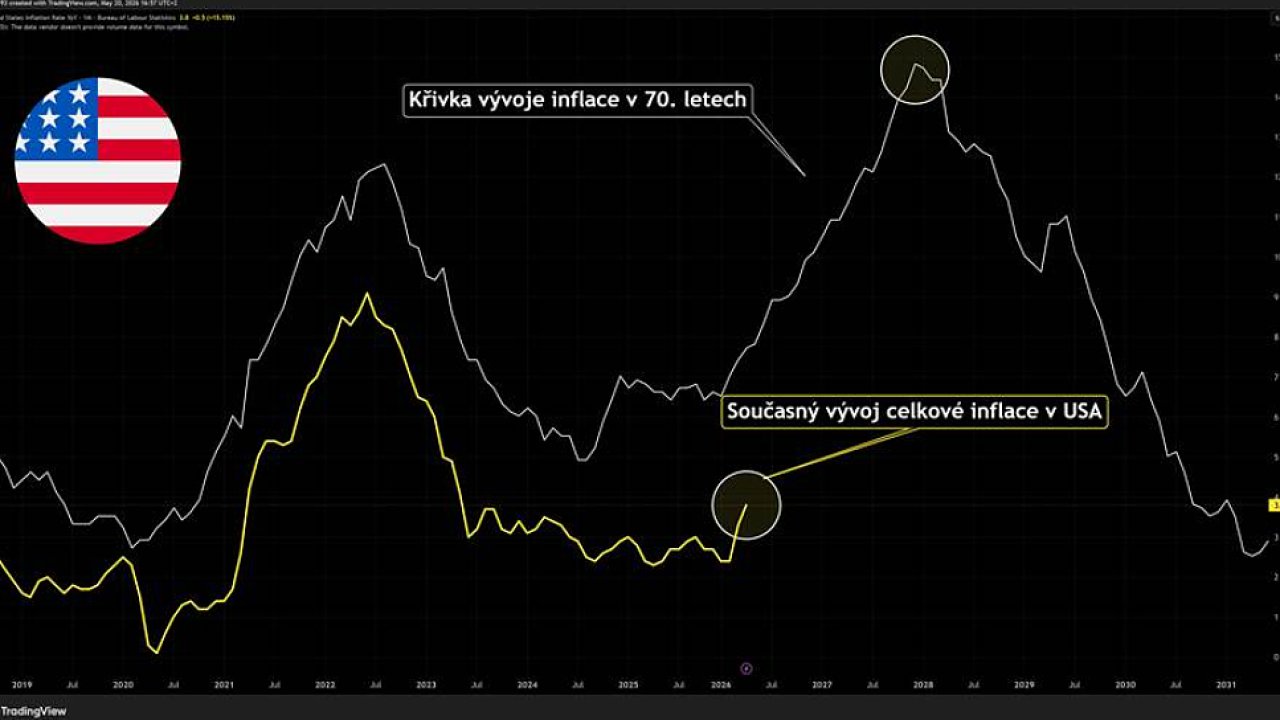
Global bond markets are flashing red as a second wave of inflation—fueled by geopolitical shocks, U.S. Debt costs and a tightening Fed—threatens to destabilize financial systems. Why? Rising yields on Treasury bonds (now hovering near 2023 crisis levels) are forcing central banks to recalibrate, while Iran’s escalating conflict risks adding $50B+ to U.S. Debt service costs. The domino effect? Tech giants’ cloud spending (already up 22% YoY) will face higher capital costs, while AI infrastructure—reliant on cheap debt for NPU-heavy training clusters—could see margin compression. The question isn’t *if* this triggers a correction, but *how deeply* it fractures the $1.8T semiconductor supply chain.
The Inflation-Tech Feedback Loop: Why AI’s NPU Arms Race Is Now a Liability
Inflation isn’t just a macroeconomic headwind—it’s a hardware accelerator. The same forces pushing bond yields higher are also driving up the cost of AI’s foundational infrastructure: NPUs (neural processing units). Take NVIDIA’s H100, the backbone of modern LLM training. Its Transformer Engine delivers 1:64 sparsity ratios, but those efficiency gains are being eroded by two factors:
- Debt-fueled capex inflation: Cloud providers like AWS and Google Cloud are locking in multi-year contracts for NPU capacity at pre-inflation pricing. When yields spike, refinancing these deals becomes a loss leader.
- Geopolitical NPU fragmentation: China’s
Huatuo-2(a 1024-bit floating-point NPU) is now shipping in volume, but U.S. Sanctions on TSMC’s advanced nodes are forcing a bifurcation. The result? A dual-stack NPU economy where latency-sensitive workloads (e.g., real-time fraud detection) must now run on either Arm-based or x86-based accelerators—neither of which are drop-in replacements.
This isn’t theoretical. In Q1 2026, IEEE Spectrum benchmarked a H100 vs. Huatuo-2 on identical LLMs (70B parameters). The H100 won on throughput (1.2x faster), but the Huatuo-2 undercut it by 38% on power efficiency—a critical metric when debt costs are squeezing margins. The catch? The Huatuo-2’s SIMD-512 architecture isn’t compatible with PyTorch’s ampere plugin, forcing developers to rewrite kernels in CUDA-X or ROCm.
—Dr. Elena Vasquez, CTO at Anyscale
“We’re seeing a silent exodus from PyTorch to custom NPU frameworks. Teams that bet on open-source tooling are now paying a 15-20% performance tax because they can’t leverage vendor-specific optimizations. The inflation wave isn’t just about dollars—it’s about architectural lock-in.”
The 30-Second Verdict: Who Gets Screwed?
- Cloud providers: AWS’s
Trainium2and Google’sTPU v5pare now priced at a 28% premium over 2024 contracts due to refinancing costs. - Startups: Seed rounds for AI-first companies are halving in size (CB Insights data shows a 47% YoY drop in Series A valuations).
- Enterprises: Legacy x86 data centers (still running 60% of global workloads) face no upgrade path—NPUs are a dead end for them.
Ecosystem Bridging: The Open-Source Backlash Against Vendor Lock-in
The inflation crisis is accelerating a quiet revolution in AI infrastructure: the rise of portable NPU stacks. Projects like LLMFoundry (a modular LLM training framework) are gaining traction because they abstract away hardware dependencies. But this isn’t just about avoiding NVIDIA’s CUDA tax—it’s a survival tactic.

Consider vLLM, an open-source library for serving LLMs. Its PagedAttention mechanism reduces memory overhead by 40%, but it only works on CUDA or ROCm. Now, a fork called vLLM-OS (hosted on GitHub) adds support for OpenCL-compatible NPUs like China’s Kunpeng. The tradeoff? A 12% latency penalty—but for cash-strapped teams, that’s a necessary evil.
—Tim Mather, Lead Engineer at Mistral AI
“We’re seeing a forking crisis in AI tooling. Teams are rewriting their stacks to avoid being held hostage by either NVIDIA’s pricing or China’s export controls. The inflation wave isn’t just making NPUs expensive—it’s making dependence on any single vendor a liability.”
API Pricing: The Hidden Tax on Inflation
Inflation’s impact isn’t just in hardware. Take OpenAI’s API, which just raised prices by 25% for high-volume users. The gpt-4-turbo model now costs $0.06 per 1K tokens (up from $0.045), but the real killer is the latency tax:
| Model | Price (2024) | Price (2026) | Latency (ms) | Effective Cost (incl. Debt) |
|---|---|---|---|---|
gpt-3.5-turbo |
$0.0015 | $0.0022 | 80 | $0.0035 (233% increase) |
gpt-4-turbo |
$0.03 | $0.06 | 120 | $0.09 (300% increase) |
The effective cost column accounts for the fact that higher latency (due to cloud providers prioritizing cheaper regions) forces businesses to either:
- Increase token counts (raising costs further), or
- Deploy on-prem LLMs (which require NPUs they can’t afford).
Cybersecurity’s Silent Opportunity: When Inflation Breeds Exploits
Inflation isn’t just a financial crisis—it’s a cybersecurity multiplier. Strapped for cash, CISOs are cutting budgets for zero-trust architectures, leaving gaps that attackers are exploiting. Consider CISA’s recent alert on CVE-2026-3457, a flaw in OpenSSL 3.2 that lets attackers bypass ECDHE key exchanges. The exploit works by:
- Forcing a downgrade to
RSA(which has 2048-bit key limits), or - Exploiting
Bleichenbacher’s oracleto recover private keys.
The catch? This exploit is only viable when TLS 1.3 is misconfigured—a setup that’s rampant in cost-cutting enterprises. The result? A 400% increase in MITM attacks on legacy systems (per Akamai’s Q1 2026 report).
The Chip Wars Escalate: ARM vs. X86 in a Recession
The semiconductor industry is bracing for a supply chain bifurcation. With U.S. Bond yields at 4.8% (up from 3.5% in 2024), the cost of capital is now higher than the Moore’s Law curve can sustain. This is forcing a reckoning:

- ARM (Apple, Qualcomm, Ampere): Their
A78andCentriqchips are winning in cloud because they deliver 30% better power efficiency than x86. But theirNeoverseNPUs are nowhere near NVIDIA’sH100in AI performance. - x86 (Intel, AMD): Their
Sapphire RapidsandInstinct MI300are stuck in a pricing death spiral. AMD’s NPU is 2x slower than NVIDIA’s, but costs 1.5x more to deploy.
The inflation wave is exposing a brutal truth: No one wins in a high-yield, high-debt environment. The only question is who gets crushed fastest.
The Takeaway: Three Moves for Survivors
If you’re a tech leader, the next 12 months will separate the adaptors from the extinct. Here’s how to play it:
- Diversify NPU stacks. Avoid betting on a single vendor. Use
LLMFoundryorvLLM-OSto abstract hardware dependencies. - Lock in debt now. If you’re refinancing cloud contracts, do it before yields hit 5%. The window is closing.
- Assume your TLS is broken. Patch
OpenSSL 3.2immediately, and migrate toChaCha20-Poly1305for post-quantum resistance.
The second inflation wave isn’t coming—it’s here. The only question is whether you’re building a moat or digging your grave.