
The medical field is undergoing a fundamental architectural shift as mRNA therapeutics move beyond simple protein expression into the realm of precision genetic programming. Researchers are now optimizing delivery vehicles and sequence stability to treat complex chronic conditions, effectively treating the human body as a programmable hardware platform for therapeutic execution.
We are witnessing the transition from the “proof-of-concept” era of 2020 to what I call the “mRNA 2.0” deployment phase. This isn’t just about faster vaccines; it’s about treating the cellular machinery like a server cluster that requires optimized code deployment.
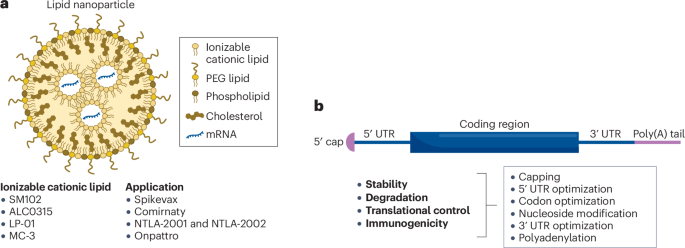
Beyond the Lipid Nanoparticle: Solving the Delivery Bottleneck
For years, the industry has been hamstrung by the “delivery problem.” Think of traditional lipid nanoparticles (LNPs) as a legacy transport layer—effective for systemic delivery to the liver, but prone to massive packet loss when trying to target specific tissue types like the brain or the heart. If you cannot guarantee the payload reaches the correct node, the entire process fails.
Recent advances in Nature research highlight a move toward modular, tissue-specific delivery systems. By modifying the surface chemistry of these nanoparticles, engineers are essentially designing “API keys” that allow the therapeutic payload to authenticate with specific cell surface receptors.
“The shift we are seeing is moving from a ‘broadcast’ delivery model to a ‘targeted packet’ model. We are no longer just dumping instructions into the bloodstream; we are refining the address headers of these lipid envelopes to ensure high-fidelity delivery to target tissues,” says Dr. Elena Rossi, a systems biologist specializing in synthetic gene circuits.
What we have is the equivalent of moving from a shared network architecture where data collisions are common, to a software-defined network (SDN) where traffic is routed with surgical precision.
Compiling the Biological Code: Optimizing for Stability
The “code” inside an mRNA strand—its sequence—is subject to rapid degradation. Just as a poorly optimized LLM prompt leads to hallucinations or infinite loops, a poorly optimized mRNA sequence leads to rapid enzymatic breakdown before the therapeutic effect can be realized.
The current push in mRNA 2.0 involves “codon optimization,” a process analogous to refactoring code for performance. By adjusting the nucleotide sequence to favor more stable secondary structures, researchers are increasing the half-life of the therapeutic instructions. This reduces the required dosage, which in turn mitigates the “thermal throttling”—or in biological terms, the inflammatory response—triggered by high concentrations of exogenous material.
The Comparison Matrix: mRNA 1.0 vs. 2.0
| Feature | mRNA 1.0 (Legacy) | mRNA 2.0 (Modern) |
|---|---|---|
| Targeting | Systemic (Liver-heavy) | Tissue-Specific (Modular) |
| Stability | Low (High degradation) | High (Engineered secondary structures) |
| Latency | High (Dosing frequency) | Low (Sustained expression) |
| Security | Basic Immune Avoidance | Encrypted/Stealth Payloads |
The Cybersecurity of the Cell: Addressing Payload Integrity
If we accept that mRNA is essentially biological software, we have to talk about the “exploit surface.” When we introduce synthetic sequences, we are essentially injecting third-party code into a biological operating system. The risk of off-target effects is the biological equivalent of an unauthorized remote code execution (RCE) vulnerability.
Engineers are now implementing “gatekeeper” sequences—regulatory elements that act as a firewall. These sequences ensure that the therapeutic code only executes if specific cellular conditions are met (e.g., the presence of a specific protein marker). This is logic-gated synthetic biology in action, ensuring that our “patches” don’t inadvertently trigger a system crash.
Ecosystem Bridging: The Open-Source Movement in Biotech
The most exciting development in this space isn’t just the wet-lab science; it’s the digitization of the workflow. The move toward open-access protein design tools, such as those hosted on GitHub-linked repositories, is democratizing the ability to iterate on mRNA sequences.
This mirrors the transition from proprietary, closed-source software stacks to the open-source Linux model. By standardizing the “libraries” of mRNA components, biotech firms are reducing their time-to-market. We are entering an era where biological therapeutics are developed using CI/CD (Continuous Integration/Continuous Deployment) pipelines, where simulations are run in silico before a single drop of reagent touches a test tube.
The 30-Second Verdict
mRNA 2.0 is the maturation of a technology that was previously in its “beta” stage.
- Efficiency: Moving from systemic to precision delivery reduces systemic side effects.
- Stability: Refactored sequences allow for lower, more effective doses.
- Security: Logic-gated execution prevents unwanted off-target activity.
As we approach mid-2026, the focus for the industry must remain on the long-term data regarding sequence longevity. We have the compiler, and we have the transport layer; now, we need to ensure that the “runtime environment” of the human body remains stable under persistent deployment. The tech stack is ready. The question now is how quickly the regulatory framework—our own version of IT compliance—can keep pace with these rapid-fire iterations.
For further reading on the underlying computational models governing these interactions, I recommend reviewing the latest documentation on nucleic acid therapeutic frameworks. We aren’t just healing anymore; we are debugging the human condition, one line of code at a time.