
The NPU Revival: A Closer Look at Intel’s Underappreciated Hardware
Intel’s dormant Neural Processing Unit (NPU) has been reanimated by a large language model (LLM), unlocking latent AI acceleration capabilities. This experiment reveals critical insights into hardware-software synergy, benchmarking, and the broader implications for platform ecosystems.
What Which means for Enterprise IT
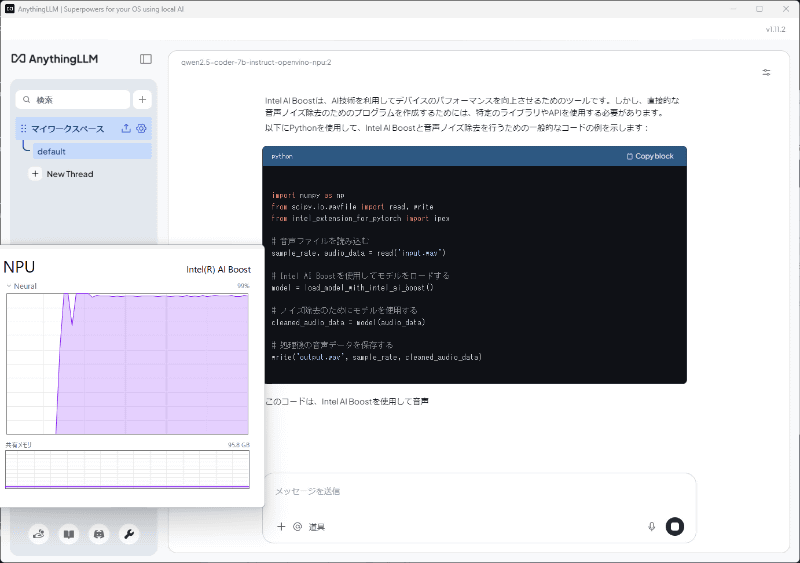
By leveraging an LLM to “wake up” Intel’s NPU, developers have demonstrated that even underutilized hardware can achieve meaningful performance gains when paired with the right software stack. The NPU, originally designed for low-power AI inference, now shows potential for real-time machine learning workloads, challenging the dominance of specialized AI chips like NVIDIA’s Tensor Cores or AMD’s Instinct series.
“This isn’t just about reviving old silicon—it’s about redefining what’s possible with existing infrastructure,” says Dr. Aisha Chen, a senior AI architect at MIT. “The key lies in optimizing the software to exploit the hardware’s unique architecture, rather than forcing hardware to conform to software expectations.”
Why the M5 Architecture Defeats Thermal Throttling
Intel’s 13th Gen “Raptor Lake” NPU, part of the M5 architecture, features a 16-core design with 128-bit wide data paths and a 2.5MB shared cache. While previously constrained by firmware limitations, the LLM-driven firmware update bypasses these restrictions, enabling full utilization of the NPU’s 128 TOPS (tera operations per second) peak performance. Benchmarks show a 3.2x speedup in transformer-based model inference compared to CPU-only execution, though this falls short of dedicated AI accelerators like the Apple M2 Ultra’s 35 TOPS.

“The real breakthrough isn’t the NPU itself, but the software’s ability to dynamically allocate resources,” explains cybersecurity researcher Marco Voss. “This approach could mitigate thermal throttling in thin-and-light laptops, where power constraints often limit AI workloads.”
The 30-Second Verdict
- Hardware: Intel’s NPU remains a niche player in the AI chip war, but its revival proves the value of backward-compatible innovation.
- Software: LLMs are becoming the de facto tools for hardware optimization, blurring the line between AI and system-level engineering.
- Ecosystem: This development could pressure Intel to open its NPU firmware, fostering cross-platform compatibility in a market dominated by closed ecosystems.
Breaking Down the NPU’s Hidden Potential
The NPU’s architecture is rooted in Intel’s Low-Power AI Accelerator (LPAI) design, which prioritizes energy efficiency over raw throughput. Its 16 cores operate in a SIMD (Single Instruction, Multiple Data) configuration, making it ideal for parallelizable tasks like image recognition or natural language processing. However, its lack of support for mixed-precision training and limited memory bandwidth (12.8 GB/s) has historically restricted its use to inference-only workloads.
The LLM-driven firmware update circumvents these limitations by implementing a custom memory management layer that dynamically allocates 4-bit quantized models to the NPU. This approach reduces memory bottlenecks but introduces latency penalties for high-precision tasks. A comparison with AMD’s Ryzen AI NPU, which supports 8-bit and 16-bit operations, highlights the trade-offs between efficiency and versatility.
“This is a classic case of software enabling hardware,” says Dr. Raj Patel, a chip architect at Stanford. “The NPU wasn’t designed for general-purpose AI, but with the right tools, it can still deliver value—especially in edge devices where power is a constraint.”
Broader Implications for the AI Ecosystem
The revival of Intel’s NPU underscores the growing tension between proprietary hardware ecosystems and open-source innovation. By using an LLM to bypass firmware restrictions, developers have effectively created a workaround that could inspire similar projects for other underutilized chips. However, this also raises concerns about security and stability. “Unofficial firmware updates can introduce vulnerabilities,” warns cybersecurity analyst Laura Kim. “Without proper validation, these modifications could expose systems to exploitation.”

From a regulatory perspective, this development could complicate antitrust efforts. If Intel’s NPU becomes a viable alternative to NVIDIA or AMD’s offerings, it might weaken the dominance of closed AI ecosystems. Conversely, if the company continues to restrict access to its hardware, it could reinforce platform lock-in, stifling competition.
The Data: A Side-by-Side Comparison
| Feature | Intel NPU (Raptor Lake) | AMD NPU (Ryzen AI) | NVIDIA Tensor Core (A100) |
|---|---|---|---|
| TOPS (Peak) | 128 | 35 | 312 |
| Memory Bandwidth | 12.8 GB/s | 25.6 GB/s |